
Awesome Papers on Learning to Hash
A curated and continuously updated collection of scholarly research on Learning to Hash, structured to support systematic exploration and academic inquiry.
Learning-Based Hashing for ANN Search: Foundations and Early Advances
NEW
Sean Moran.
2025
An accessible introduction to the field of learning-based hashing and a synthesis of its early core advances, bridging projection, quantisation, and supervised approaches for efficient similarity search.
Browse Papers by Tag
Explore the latest research by browsing papers categorized by tags. Select a tag below to dive deeper into specific topics within the field of learning to hash:
What This Site Offers
- 🔍 Access over 3,000 curated publications, organized by topic and methodological taxonomy
- 📈 Identify emerging trends in supervised, unsupervised, deep, and quantized hashing methods
- 🧠 Examine real-world applications including audio retrieval, source code search, and geospatial monitoring
- 📎 Contribute to the resource by submitting new papers or updates
What is Learning to Hash?
Nearest neighbour search involves retrieving similar items from large datasets, often in high-dimensional spaces. Learning to Hash (L2H) enhances this process by learning compact representations—typically binary codes, but sometimes real-valued or quantized forms—that preserve semantic or structural similarity. These representations enable fast and memory-efficient approximate retrieval by avoiding exhaustive comparisons.
Learning to Hash techniques underpin a broad range of applications, including large-scale multimedia retrieval, recommendation systems, source code search, scientific data mining, and real-time anomaly detection.
Selected Applications
- Source Code Search – MinHash applied to large-scale code recommendation
- Efficient Transformers – Locality-Sensitive Hashing (LSH) for computational efficiency
- Fraud Detection – Spatial anomaly detection using LSH at Uber
- Event Tracking – Social media monitoring through similarity-preserving hashing
- Image Retrieval – Scalable visual indexing with LSH at Google
How Hashing Works
Learning to hash involves training a model to encode data points into compact representations, often binary hash codes. These are used to index items into hash tables. During retrieval, only a subset of nearby buckets are examined, significantly reducing the search space compared to exhaustive nearest neighbour methods.
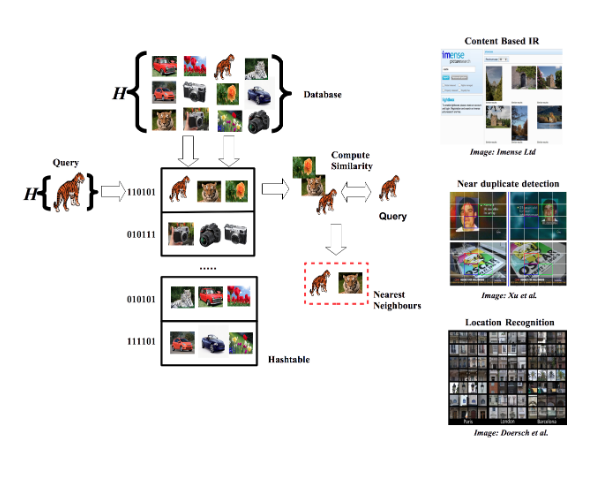
Example of LSH in action, from the PhD thesis of Sean Moran.
Contribute to the Collection
This site is maintained as a community-driven literature review. If you have authored or come across a relevant paper, we encourage you to contribute via our submission form or GitHub pull request. See the Contributing page for details.
To explore further, view the full set of indexed papers on the All Papers page, or visit the Resources section for foundational materials and curated tools.
Copyright © Sean Moran 2025. All opinions are my own. If you find this resource helpful, a coffee ☕ is always appreciated to support its upkeep.